
The Ultimate Guide to Choosing the Right Machine Learning Algorithm from Day One.
Discover how to choose ML models for your business problems with this step-by-step guide using the CRISP-DM framework.

🙋🏻♀️ Hi there. I am Meri. Welcome to my newsletter, where I share how Machine Learning and Data Science are applied in the industry.
I am a Data Science Practitioner and a founder of the Break Into Data community. Join our Discord Server for more resources and networking opportunities.
Many aspiring Data Scientists believe that implementing machine learning models follows a straightforward, cookie-cutter approach. When in reality, it is a complex, iterative process filled with nuances.
If you want to be a highly sought-after Data Scientist or ML Engineer, prioritize understanding when and how to apply machine learning before writing a single line of code.
This article will explore fundamental concepts in applied ML within a business context, including CRISP-DM, to help you choose the right model for your use case.
What we will cover:
Why learn Machine Learning Engineering in 2024?
Most common ML model use cases by industry.
How to gather Business Requirements with the CRISP-DM framework.
Data Understanding.
Data Preparation.
How to select an ML model for your use case.
Model Evaluation.
This article was prepared for Break Into Data Community members as a guide for the 30-Day ML challenge. If you want to find more relevant resources, explore our previous articles here:
Read until the end to see how you can get involved in our open-source projects and improve your ML skills.
0. Why learn ML Engineering in 2024?
Instead of trying to convince you of the Machine Learning Business and Career opportunities, I want you to go over a regular day with me in 2024:
Morning: You wake up with an AI-powered alarm clock like Sleep Cycle which analyzes your sleep patterns and wakes you up during the lightest phase of sleep, ensuring you feel the best.
Personal devices: You open your eyes and unlock your phone using facial recognition such as Apple’s Face ID.
Social Media: You tap on your social media apps: IG, Twitter, and Linkedin, that use Convolutional Neural Networks to personalize your news feed.
Home Devices: You check for the weather using Alexa, which uses advanced Natural Language Processing (NLP) and automatic speech recognition (ASR).
Commute: You drive to work using Google Maps which suggests the fastest routes with Clustering and Time-Series Forecasting algorithms.
And all this happens in the morning before you even get to work. Keep in mind, that we haven’t even discussed the breadth of enterprise solutions yet.
I hope you see my point by now. If not, check the image below.

Let’s explore some statistics in the ML industry:
The global ML market is valued at $204.30 billion in 2024, and is projected to achieve a CAGR of 17.15%, which will capture a whopping $528.10 billion by 2030!
What about job prospects in ML?
High Demand for MLEs: According to the World Economic Forum's 2023 Future of Jobs Report, the field is expected to grow by 40% over the next five years, translating to the need for one million new machine learning specialists by 2027.
Competitive Salaries: Machine learning engineers are among the highest-paid data professionals, with salaries at top Tech companies ranging from $231K to $338K per year.
If you are reading this article, I presume, you are already on your way to becoming a Data Scientist and ML engineer. Kudos to you!
Now let’s explore your options.
1. Common Machine Learning Applications by Industry
How does the industry take advantage of ML?
I created a table with the most common ML models and their industry use cases below. As you can see most of the business applications still revolve around traditional Machine Learning Algorithms. More complex Statistical Algorithms like Neural Networks are still relatively new.
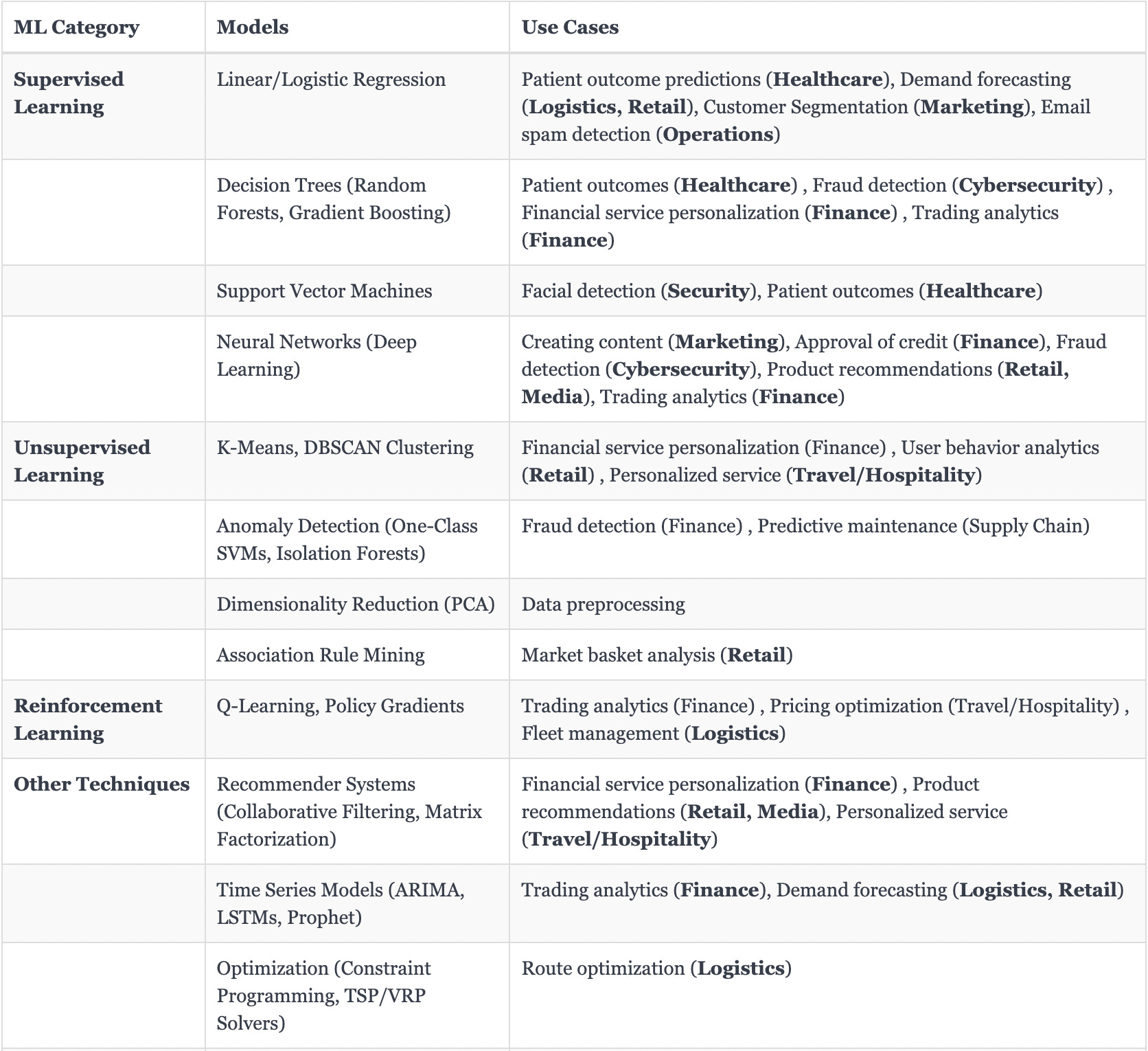
Given the variety of Data Science applications, it is easy to get overwhelmed.
Instead of learning 10 ML algorithms in parallel, I want you to implement a T-shaped learning approach.
T-Shaped Expertise in the Context of Machine Learning
T-shaped expertise is a combination of deep knowledge in one specific area (the vertical bar of the "T") and a broad understanding of related areas (the horizontal bar of the "T").
For example, you might choose to specialize in either one or sometimes two of these:
Natural Language Processing (NLP): Developing advanced algorithms to understand and generate human language.
Computer Vision: Creating systems that can interpret and make decisions based on visual data.
Reinforcement Learning: Designing models that learn optimal behaviors through trial and error in dynamic environments.
Time Series Analysis: Focusing on predicting future values based on historical data in domains such as finance.
Specializing in one area allows you to become an expert, contributing significantly to cutting-edge advancements and solving complex problems.

But!
Don’t get me wrong. It doesn’t mean you are isolated from the rest of Data Science techniques. In fact, anchoring in one area can give you a significant advantage in understanding and implementing other ML models.
Consider this:
Let’s say, you specialize in NLP (depth) but also have a good understanding of computer vision, reinforcement learning, and basic machine learning algorithms (breadth). This will allow you to:
Develop sophisticated NLP models while considering insights from computer vision, such as using visual context to enhance text understanding. (Multimodal AI)
Implement reinforcement learning techniques in NLP applications, like optimizing dialogue systems in chatbots.
Apply general machine learning best practices to improve model performance and deployment efficiency.
Every ML algorithm has its own challenges and deployment requirements. But today let’s focus on selecting ML models based on Business needs.
2. How to Gather Business Requirements
Okay. Now that you have decided what kind of Data Scientist you want to be.
Let’s explore real-life application frameworks.
According to CRISP-DM (Cross-Industry Standard Process for Data Mining), a widely used methodology for managing the machine learning lifecycle,
We should always start with “Business Understanding”. See image.
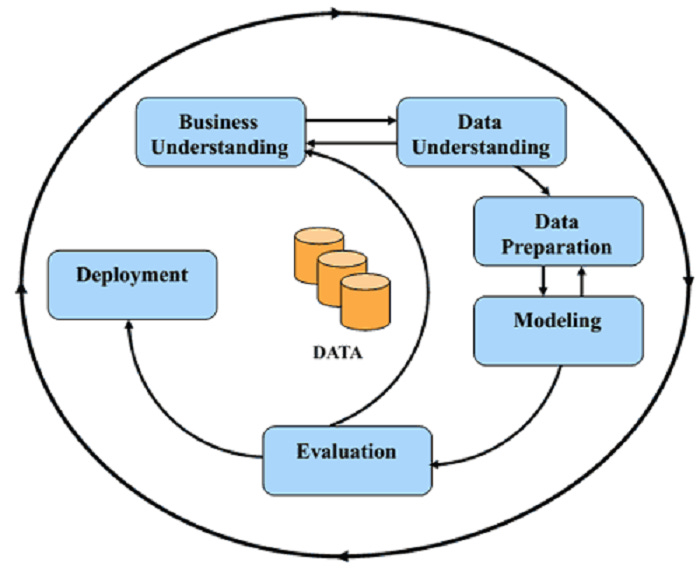
Here is how:
Problem Identification
Understand and define the specific issue a business is facing.
Evaluate the Need for Machine Learning
Not every problem needs a machine-learning solution.
Sometimes, simpler rule-based systems or heuristics might be enough.
Define Metrics for Business Success
Develop clear, measurable metrics to track the success of the project:
For example, set quantitative business targets like "reduce spam complaints by 50%" or “increase conversion rate by 15%”.
Let’s take an example with Recommendation System for a new E-Commerce store:
Problem Identification: The goal is to increase sales by 20% by leveraging user browsing and purchasing history.
Evaluate Need for ML: In our case, traditional recommendation methods are insufficient. ML can analyze large volumes of user data to provide personalized recommendations.
Define Business Success Metrics: Set goals to increase CTR on recommended products by 15%, average order value (AOV) by 10%, and overall sales by 20%. Measure success through user engagement and sales metrics.
3. Data Understanding
Now, let’s go over the most crucial step in your ML application that will define the trajectory of your project.
We all know by now that machine learning is all about deriving patterns from Data. Therefore, Data is foundational to the success of our project.
Let’s consider common obstacles in this stage:

Insufficient Data
Often, we set ambitious goals without realizing that available data might be insufficient. So it becomes impossible to address the previously stated problem.
To give you an example from personal experience:
Initially, our Break Into Data community engineers wanted to build a regression model that predicts the number of Data Science job openings for every day of the year in 2024. Since we couldn’t find available historical datasets for the past 5-10 years, we decided to reframe our project altogether!
Before declaring a project you must first explore all the available data!
Small datasets
If we’re dealing with a smaller dataset, we have fewer options. In this case, we have to pick a model that has low complexity to avoid overfitting the model to the data. Good examples would then include linear models (logistic and linear regression) and Bayesian models (Naive Bayes).
Number of Features and Data Points
On the other hand, if we have a large number of features and data points, we need to consider more complex ML models. Algorithms, like neural networks and gradient boosting, can handle much higher dimensionality, in addition to automatically performing feature engineering. Algorithms like SVM, and KNN will likely not be able to handle high dimensionality as well.
Steps to follow:
Collect Data
Describe Data
Explore Data with EDA
Verify Data Quality
By understanding your data options thoroughly you can address potential limitations and roadblocks early on.
4. Data Preparation
This phase is often the most time-consuming part of the project, usually, we end up spending more than 50% of our time here.
Why?
Because Data is ALWAYS messy. And the performance of your algorithm depends on its quality.
Here is the entire process of Data Preparation according to CRISP-DM:
Data Selection.
Here you decide which columns in your dataset go into your model and which stay. You also need to understand whether you have a sufficient amount of data to proceed with your project.
Data Cleaning.
Here you can handle missing values, remove noise and outliers, and correct inconsistencies.
Constructing Data.
This involves creating new attributes or features from the existing data. It can include:
Feature Engineering: Generating new variables that can help improve the performance of the model. This might involve combining existing variables, creating interaction terms, or applying mathematical transformations.
Aggregation: Summarizing data at different levels of granularity, such as aggregating daily data to monthly data.
Derivation: Creating new variables based on domain knowledge, such as calculating the age of a customer from their birthdate.
Integrate Data.
Your data may come from multiple disparate sources. This task involves merging those datasets into a unified view by using techniques like data consolidation and data federation.
Format Data.
This task covers reformatting or encoding the final dataset to make it compatible with the modeling tools that will be used in the subsequent phases1.
5. Selecting a model
Choosing the right machine-learning technique involves (1) understanding the nature of your problem, (2) the type of data you have, and (3) the specific algorithms that can solve these problems.
Here’s a 4-step guide to help you navigate this process, along with actionable points and examples.

Identify the Category of the Problem: Labeled vs unlabeled.
Supervised Learning: Used when you have labeled data. Common tasks include classification (e.g., spam detection) and regression (e.g., predicting house prices).
Unsupervised Learning: Used when you have unlabeled data. Common tasks include clustering (e.g., customer segmentation) and association (e.g., market basket analysis).
Determine the Task at hand:
Classification: Assigning data to predefined categories (e.g., image recognition).
Regression: Predicting continuous values (e.g., stock prices).
Clustering: Grouping similar data points (e.g., segmenting users based on behavior).
Dimensionality Reduction: Reducing the number of features (e.g., PCA for feature extraction).
Recommender Systems: Suggesting items to users (e.g., movie recommendations)
Define Metrics for Deployment Success
How important is accuracy? If so what is your minimum acceptable threshold?
What about inferencing or training speed?
Scalability and reproducibility?
What about the cost of model training and inferencing?
Account for Explainability vs Performance:
Often, there is a direct trade-off between explainability and performance/accuracy. For instance, if we desire an interpretable algorithm, we might opt for linear regression, where we can see the contribution of each feature coefficient to the final target value. However, this simplicity often comes at the cost of predictive power.
On the other hand, more complex models like deep neural networks or ensemble methods can capture intricate patterns within the data, leading to higher accuracy. Yet, these models are often considered "black boxes". This opacity can be problematic in high-stakes applications where understanding the logic behind a model's predictions is crucial.
As a side note, always start with simple and slowly iterate your way to more complex models.
Are you starting to understand why this process is iterative?
6. Evaluation
The goal here is to verify that the models are not only technically sound but also fit into the budget and are aligned with business targets.
Evaluate Model Performance:
Here we can compare model performance against baselines.
Evaluate Results: Assess the model's performance against the business success criteria. Summarize whether the model meets the initial business objectives.
Review Process: Ensure that the model was built correctly and address any quality assurance or data privacy issues. Document the entire process.
Determine Next Steps: Based on the evaluation and review, decide whether to proceed to deployment, iterate further on the model, or implement a different ML technique altogether.
Final thoughts
This article is meant to be a practical overview on how to select an ML algorithm based on your business problem and available resources.
In the future, we will talk more about deployment methods based on Break Into Data’s open-source projects.
If you want to get involved in building the infrastructure for our community feel free to reach out directly to me on Linkedin.
Resources:
If you are early in your Data Science or Machine Learning journey save these links:
Break Into Data Handbook - You will find all the resources to start your Data Science Learning journey. Make sure to start the repos.
30-Day ML challenge Github repo - Here you will find guidelines and resources to build and deploy your own ML application.
Example project guide from Break Into Data - This is an example project for 30-Day ML challenge participants. I will publish another in-depth article on the deployment of this project soon, stay tuned.
Youtube channel - We post our Speaker Session Events with Data Scientists and industry experts every week.
Join our active Discord Server, where you can meet and work silently in our voice channels next to other Data Scientists, Analysts, and Engineers.
Happy Coding!