
4 Main LLM Engineering levels: which one should you choose?
Read about 4 unspoken levels of LLM engineering and their impact on your career. From best practices on Prompt Engineering and RAG to pre-training your own models.

🙋🏻♀️ Hi there. I am Meri. Welcome to my newsletter, where I talk about the best ML engineering practices in the industry.
I am a Machine Learning Engineer and a Technical Founder at Break Into Data. Subscribe to my newsletter for more ML & Data resources and guest sessions with industry leaders!
After building LLM applications for both internal use at Break Into Data and for consulting clients, I noticed 4 distinct LLM implementations that correspond with 4 different LLM career trajectories:
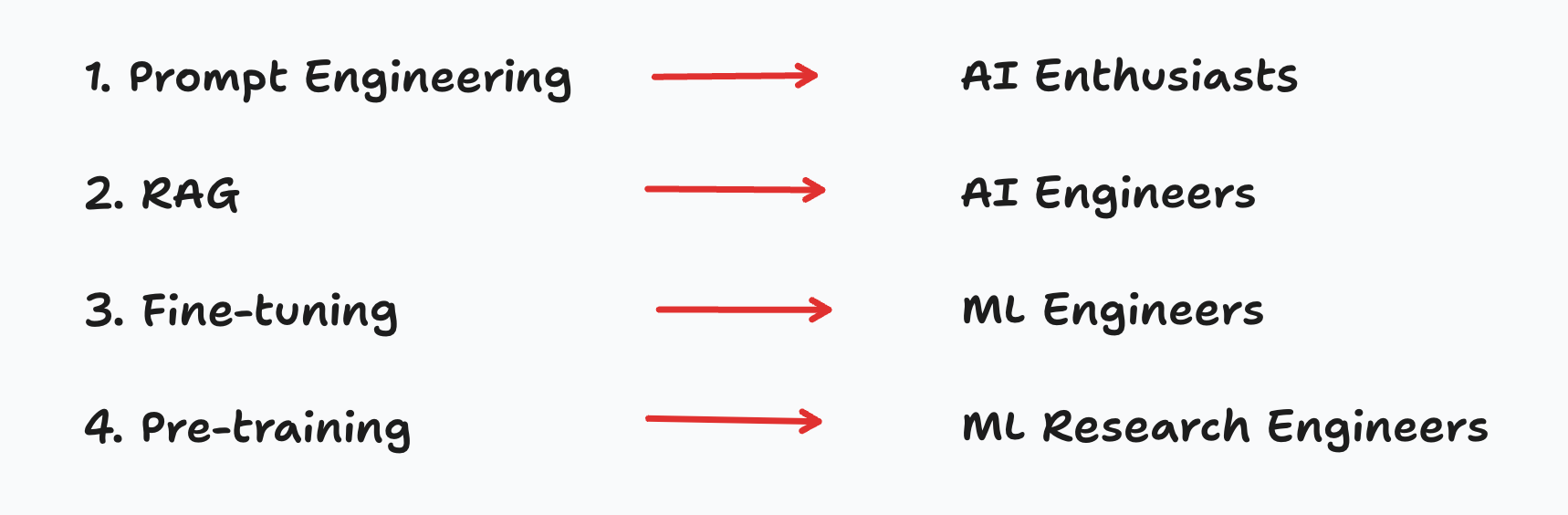
In this article, I will explore each track, highlighting its technical limitations and business opportunities.
The goal of this newsletter is to provide clarity around LLM Engineering for anyone interested in building a successful career in generative AI.
When did it all start?
While NLP and LLMs had numerous pivotal moments (which you can read about in this article written by my co-founder, Kostya Numan), the true revolution began in 2017. The entire Deep Learning field changed forever when the paper "Attention Is All You Need" introduced the transformer architecture.
This breakthrough was successfully backed by the industry’s implementation of the paper in November 2022 with the release of ChatGPT.
Since then, LLMs have become a household name.
Investment in LLM development increased by 400% between 2022 and 2023, with VC firms pouring $100+ millions into AI startups with no clear product-market fit, but a dream. (I can't mention specific startups because it will put some of my networks in a tough spot. A story for another time. )
Meanwhile, the open-source community has been extremely busy launching new tools and libraries every single day. Check out this graph below from Chip Huyen’s blog post to see the explosion of GitHub repos in recent years.
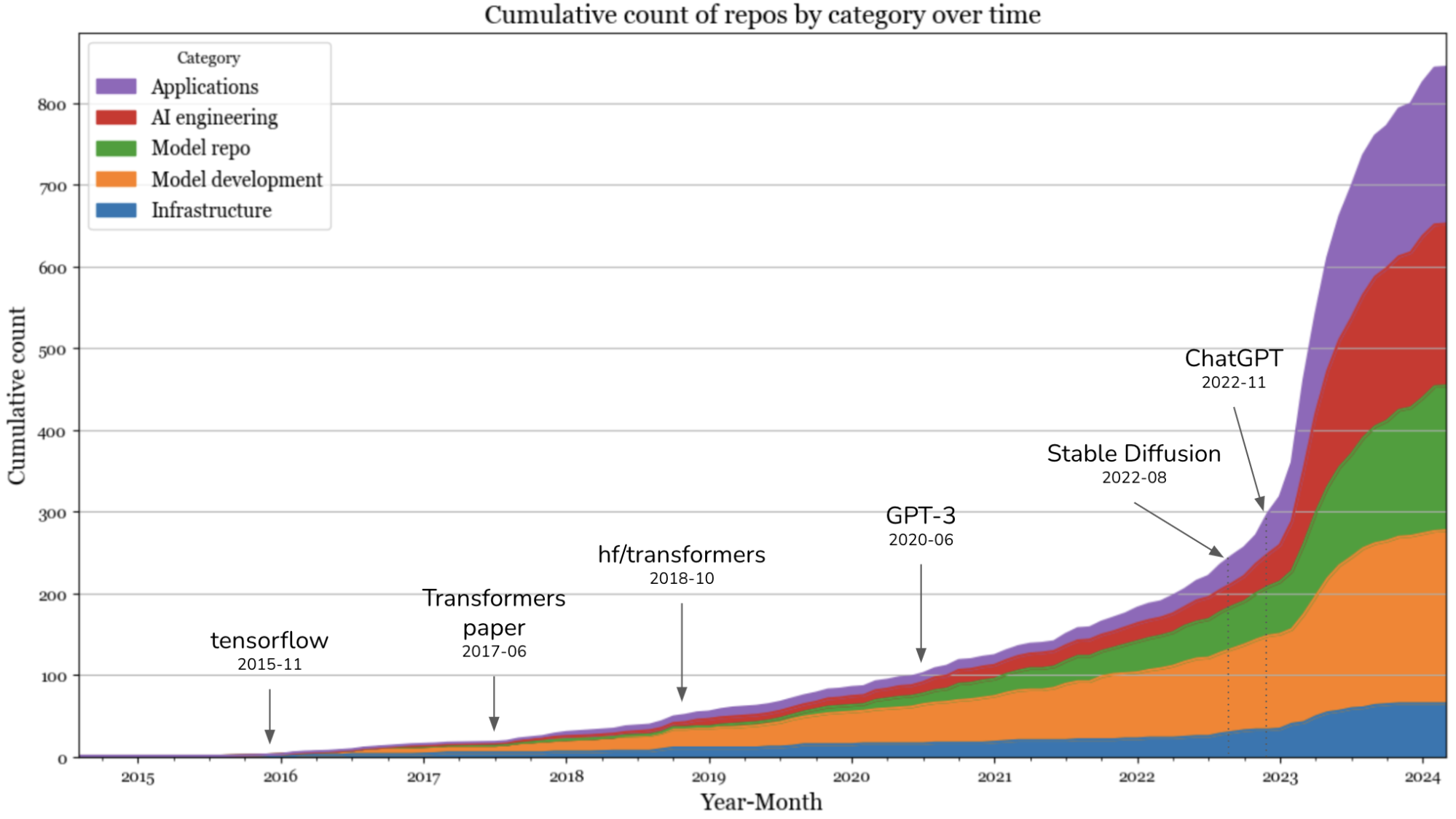
Entire new open-source platforms emerged. Just like Kaggle democratized access to large datasets for data scientists, Hugging Face democratized access to almost a million open-source models for ML engineers only in a matter of few years.
To give you a more personal perspective…
I've lived in SF, Bay Area for 10 years, and this is the most excitement I've seen around AI during my entire time here.
So what’s the issue?
Even though new research is coming out at an exponential rate, ironically, the ML community has more questions than answers, especially on the long-term LLM strategy.
Here are some of them, that we will focus on today:
What to choose: training models from scratch, fine-tuning, or RAGs?
Which career path is the best: research or engineering?
How to prioritize learning: foundational algorithms or the latest AI tools?
How to not go insane with this pace of collective innovation?
To answer these questions, we first need to agree on these 4 distinct technical LLM approaches that will help you pick a strategy for your implementation and career.
Each path has its level of complexity, time to deployment, and use cases you can see in the table below.
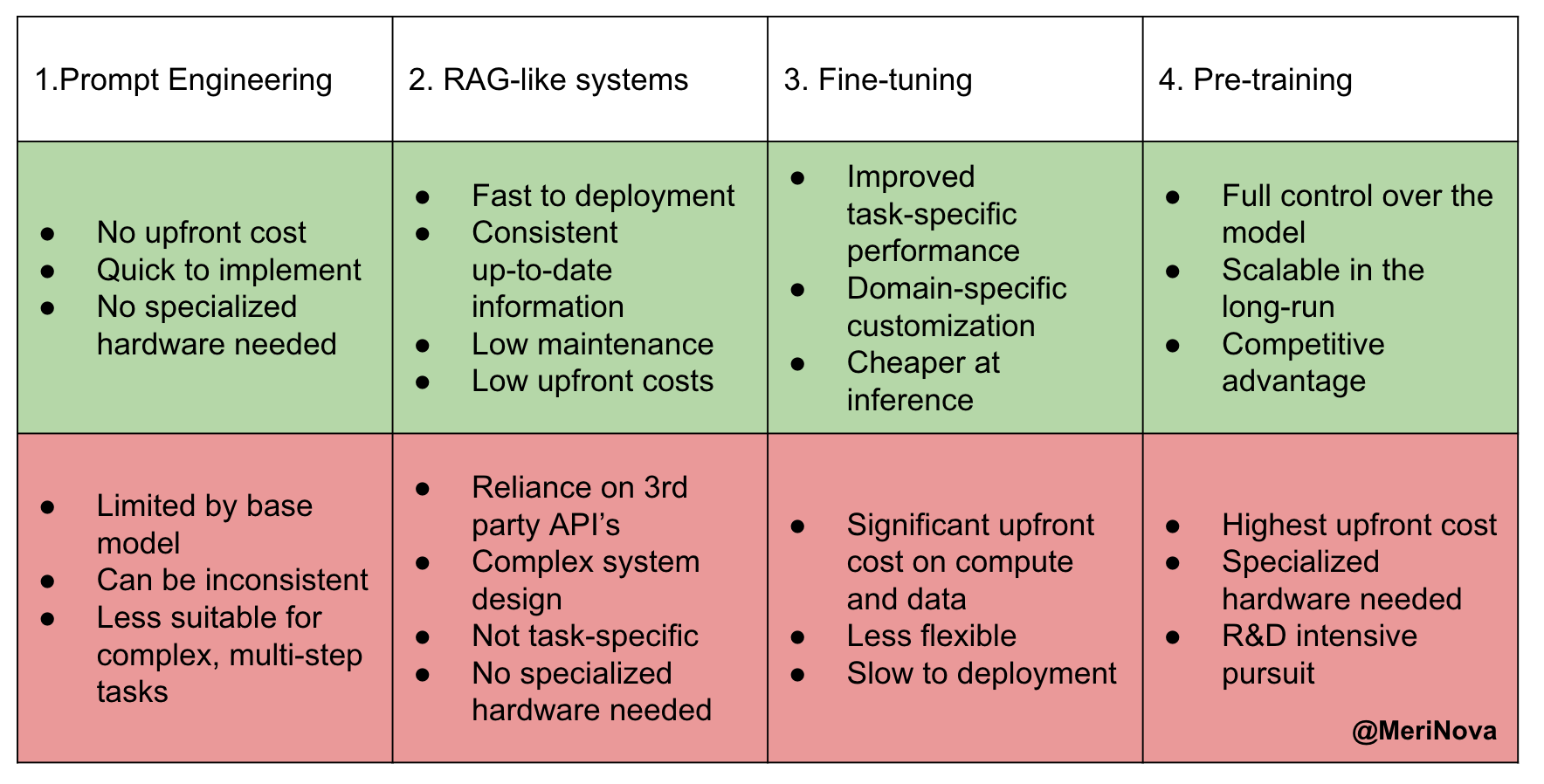
Now, let’s dive in…
I will break down each level from two perspectives: the engineering approach and the career track. I’ll also include resources, key research papers, and tutorials should you decide to dive deeper.
1. Prompt Engineering
Role: AI Enthusiast
Let’s begin with the most straightforward approach.
These days, anyone can sign up for third-party API subscriptions and create generative AI applications using a few-shot prompting example. In fact, many prototypes and MVPs are built this way.

This is also exactly how I got started with LLMs in 2022. I experimented and learned about LLM’s behavior in a production environment.
This is a great way to begin because you can gain an intuitive understanding of what language models are capable of by quickly testing and refining your ideas.
Check out DSPy, a framework that can help you systematize your approach with prompting and see prompt engineering as programming.
There are entire careers that are built around this approach. However, if you are curious about more involved ways to deal with LLMs read further.
2. RAG-Like Systems
Role: AI Engineer
This approach involves another layer of complexity by adding external datasets to existing architectures. However, you are still relying on third-party APIs.
RAG (Retrieval Augmented Generation) and its variations, such as GraphRAG, or Agentic RAG, allow engineers to improve LLM’s outputs without changing the model’s internal weights and biases.
Everyone got excited when RAG was first popularized. This was an industry hack! Now we didn’t have to invest nearly as much money on compute and training data for fine-tuning to be able to customize the models.
Here is an illustration of a simple RAG workflow.

This career path is great for people with software engineering backgrounds who have experience with system design, connecting databases, APIs, and backend systems.
An AI engineer might be a broad term for this role, but in this context, it refers to someone who can develop and deploy applications that mimic human intelligence. However, it doesn’t mean that they only work with RAG-like systems.
Remember, the industry is in its infancy, so make sure to always read the role description and don’t fall for the titles.
If you want to learn more about this approach, stay tuned for my upcoming course on RAG with Langchain. It will be available in October 2024!
3. Fine-Tuning Open-Source Models.
Role: ML Engineer
This approach is fundamentally different from the previous RAG-like architectures, as it changes the inner workings of a model. It involves taking a pre-trained open-source language model(like LLama) and adjusting its weights using a task-specific dataset to improve performance on a particular application. For example, if you want an LLM to excel at medical text analysis, customer support, or any domain-specific or task-specific application.
Efficient fine-tuning techniques like LoRA (Low-Rank Adaptation) and parameter-efficient tuning (PEFT) are used to reduce the number of trainable parameters, making fine-tuning feasible even on a single GPU.
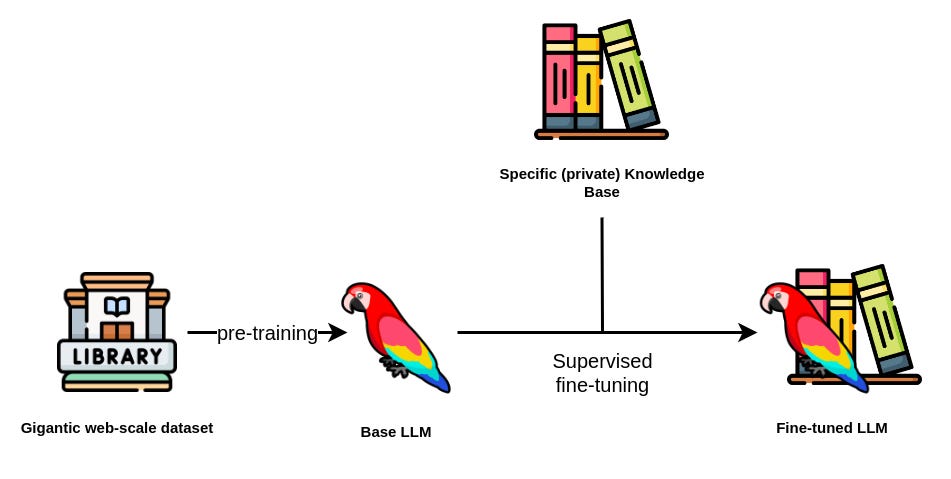
If you would like to learn more about this approach, then I highly recommend starting with this playlist from Weights & Biases on Training and Fine-tuning LLMs.
Before RAG became popular, this was a default approach for customizing LLMs. However, combining both RAG and fine-tuning is known to show the best results.
4. Pre-Tuning Models From Scratch
Role: ML Research Engineer
The most complex and resource-intensive approach is to train a large language model from scratch. A pursuit that only an ML Research Engineer or Scientist can handle. This approach is suitable for organizations with specific needs that cannot be met by existing models.
Or when companies want a competitive advantage and do not mind spending a couple of million dollars on the R&D department.
However, anyone can build a model from scratch!
If you are curious how it can be done you can pre-train a small language model by watching Sebastian Raschka, PhD ‘s recent 3-hour coding workshop video on building LLMs from the ground up.
Which approach should you choose?
Depending on your company’s resources and goals, you can either choose one of these approaches or combine them all into one to build the most resilient and robust LLM application.
If you want to build a career in LLMs, I highly recommend focusing on either RAG or fine-tuning. Around 80% of the industry uses both of these approaches because they offer the best results with minimal investment.
To learn more about the common compensation ranges, frameworks, and tools check out my recent LinkedIn post and the image below
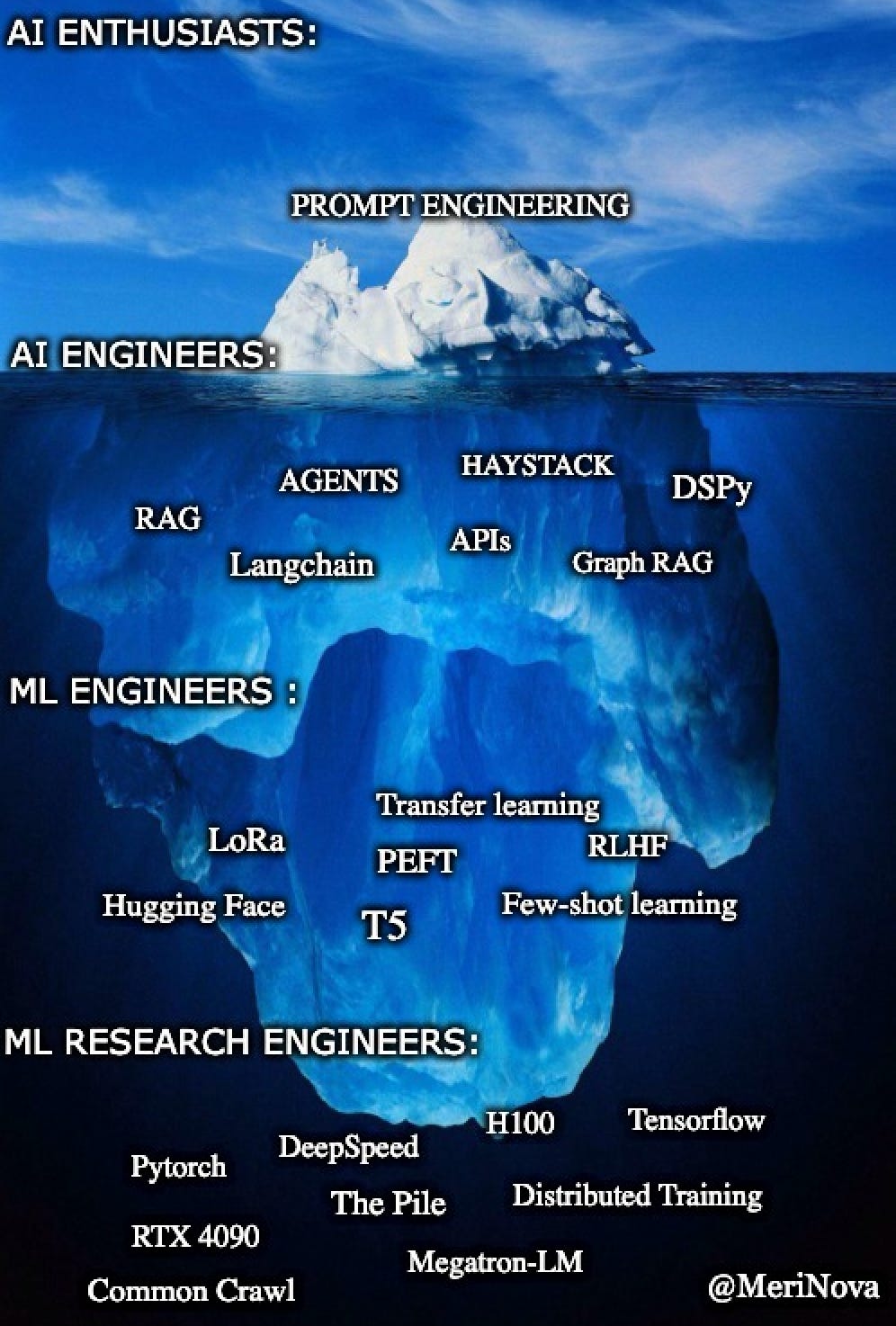
Career Advice for Aspiring LLM Engineers
If your goal is long-term job security, my main advice is to find your niche( and stick to it!
Once you will have built a domain expertise you will become a lot more valuable to hiring managers, because you will know how to implement LLM according to their unique use cases. It will set you apart from the sea of other AI enthusiasts, who only have technical skills.
On top of that, another timeless piece of advice is to master orchestration and infrastructure development.
No matter how often new models emerge or old approaches evolve, you will still need to build robust production-grade applications, that involve having:
Scalable Cloud Infrastructure
Reliable Evaluation Frameworks
High-quality Data Pipelines
Optimized Model Serving
Monitoring Systems and Version Control
Focus on these areas, and you'll always be in high demand as an ML professional, no matter which of the four approaches you choose to specialize in.
Upcoming Live Session with me
If you would like to learn more about building a career in the field of Large Language Models or generative AI, register for my upcoming Live Session - here!
Or press the button below.
Happy learning fellow ML and AI builders!
P.S. I would love to hear from you! Connect with me on Linkedin and share your thoughts on this article! I am always open to future topic suggestions.
Thanks for this article, Meri.
I have built a pre-tuned model from scratch and read about RAG and fine-tuning approaches.
Your article offers a more detailed view of the roadmap, and I appreciate the advice you gave to aspirants like me.
Great breakdown Meri! It will help a lot of people to find a roadmap